Memory copy with relocation on Commodore 128
Suppose you need to copy a full memory page (256 bytes) from one address to another using assembly on Mos 6502.
There are many ways to accomplish this task. The simplest one is a subroutine like this:
ldx #0 // 2 cycles - 2 bytes
!: lda $0400,x // 4 cycles - 3 bytes
sta $0600,x // 5 cycles - 3 bytes
inx // 2 cycles - 1 byte
bne !- // 2 cycles - 2 bytes
rts // 6 cycles - 1 byte
This example copies 256 bytes from $0400 to $0600 and requires 3328 cycles for loop and other 8 for initial ldx and rts. It also uses 12 bytes of memory.
Another version can be more flexible, in order to choose which page should be used for source and destination:
stx r + 2 // 4 cycles - 3 bytes
sty w + 2 // 4 cycles - 3 bytes
ldx #0 // 2 cycles - 2 bytes
r: lda $ff00,x // 4 cycles - 3 bytes
w: sta $ff00,x // 5 cycles - 3 bytes
inx // 2 cycles - 1 byte
bne r // 2 cycles - 2 bytes
rts // 6 cycles - 1 byte
This routine expects source page in .X and destination page in .Y. Then with some self-mod code, pages are used instead of $ff00. This example requires 3328 cycles for loop and other 16 for init and rts. It also uses 18 bytes. Before calling, there are also a ldx and ldy instructions for page settings.
At this point there are no major improvements that can be made. To write a better algorithm it is necessary to completely change the solution setup. Among the innovations that the C128 brings with it is the possibility of relocating page 0 and page 1. The relocation of pages 0/1 is carried out by changing the value of the addresses between $D507 and $D50A (see memory reference). By appropriately entering the parameters it is possible to indicate on which memory area the two pages must be mapped and also on which block (the first or second 64Kb of RAM).
Regarding copying between memory areas, let’s see how relocation can be exploited.
// Zero page location labels
.label TEMP = $fe
sei // 2 cycles - 1 byte
stx r + 2 // 4 cycles - 3 bytes
tsx // 2 cycles - 1 byte
stx TEMP // 2 cycles - 2 bytes
sty $d509 // 4 cycles - 3 bytes
ldx #0 // 2 cycles - 2 bytes
txs // 2 cycles - 1 byte
r: lda $ff00,x // 4 cycles - 3 bytes
pha // 3 cycles - 1 byte
dex // 2 cycles - 1 byte
bne r // 2 cycles - 2 bytes
ldx #1 // 2 cycles - 2 bytes
stx $d509 // 4 cycles - 3 bytes
ldx TEMP // 3 cycles - 2 bytes
txs // 2 cycles - 1 byte
cli // 2 cycles - 1 byte
rts // 6 cycles - 1 byte
This code requires 2816 cycles for loop and 31 other cycles for preparing and closing copy routine (2847 total cycles). It also requires 30 bytes of memory.
It’s 14% faster than the previous solution, it may not seem like much but in some places where few cycles are available, even 600 fewer cycles can make a difference. For example, consider using this algorithm between the raster interrupt lines.
Let’s go into detail about the algorithm to understand how it works and consider copy page at $1000 (page $10) into page $2000 (page $20). This is the initial status of memory.
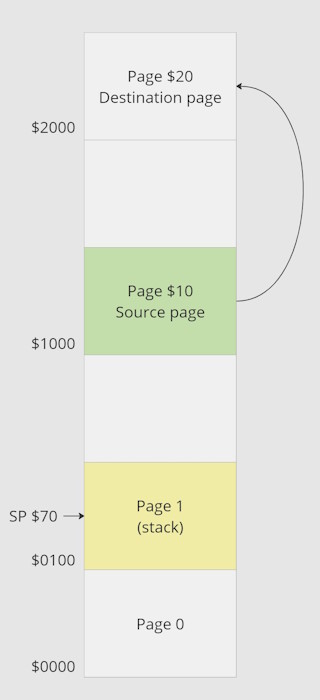
This is the initial status with page 0 and 1 located at $0000 and $0100. As expected, .X should contain source page ($10) and .Y should contain destination page ($20). Current stack is yellow.
// Disable interrupt
sei
// Self-mod code to setup lda on correct page (on .X before algorithm
// start)
stx r + 2
// Preserve current stack pointer on zero-page location
tsx
stx TEMP
// Relocate stack to destination page (on .Y before algorithm
// start)
sty $d509
After running the first part of the algorithm, memory status has changed:
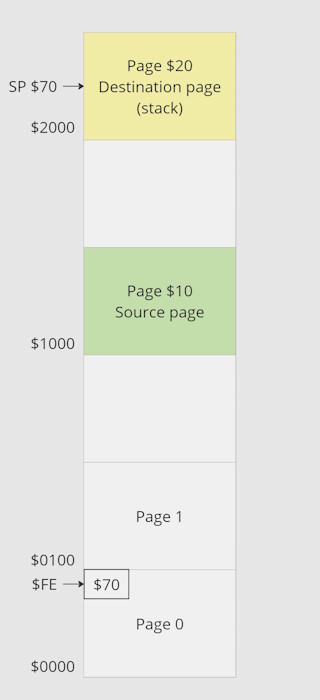
Interrupt are disabled, a self-mod code is done to point to source page and current stack pointer value (for example, $70) is copied into a zero-page location. Last operation will relocate stack from page 1 to destination page ($20).
And now the main part:
// Init index and stack pointer
ldx #0
txs
// Load byte from source page to .A
r: lda $ff00,x
// Push byte from .A to stack (which is destination page)
pha
// Decrement index and check for next loop
dex
bne r

Stack pointer is set to 0 and loop starts loading each byte from starting page and it’s pushed to stack. At first push, stack is updated from $00 to $FF and it’s decremented at each iteration. When .X reach 0, loop is stopped.
The last part, the initial environment is restored:
// Restore one-page to original mapping
ldx #1
stx $d509
// Restore stack pointer to original value
ldx TEMP
txs
// Reactivate interrupt and return to caller
cli
rts
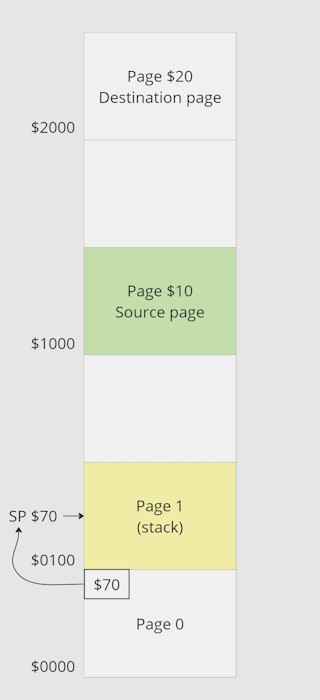
Stack page is restored to page 1 and then original stack pointer is taken from $FE and restored to original value. Lastly, interrupt are reactivated.
This can be a valid alternative if you have to be quick. It is only available on Commodore 128 because the relocation of the pages is managed by the MMU. The price to pay is greater implementation complexity.
Update 27/12/2023
Daniel Hotop sent me an improvement. There are two main differences:
- relocating of page 0 and 1
- unrolled loop
In the first example, only page 1 was relocated. In this example, page 0 is also relocated and mapped onto the source page. This trick allows you to run LDAs with Zeropage addressing instead of Indexed absolute addressing which saves a clock cycle (and also one byte).
With cycle unrolling, the size increases significantly but you can save 2 cycles for DEX and 2 cycles for BNE needed for loop handling.
This solution also requires the source page in .X and destination page in .Y.
.label TEMP = $fe
sei // 2 cycles - 1 byte
stx $d507 // 4 cycles - 3 byte
stx Src1 + 2 // 4 cycles - 3 byte
stx Src2 + 2 // 4 cycles - 3 byte
tsx // 2 cycles - 1 byte
stx TEMP // 3 cycles - 2 byte
sty $d509 // 4 cycles - 3 byte
ldx #0 // 2 cycles - 2 byte
txs // 2 cycles - 1 byte
lda $ff // 3 cycles - 2 byte
pha // 3 cycles - 1 byte
lda $fe // 3 cycles - 2 byte
pha // 3 cycles - 1 byte
// Other lda-pha pairs
lda $2 // 3 cycles - 2 byte
pha // 3 cycles - 1 byte
:Src1
lda $ff01 // 4 cycles - 3 byte
pha // 3 cycles - 1 byte
:Src2
lda $ff00 // 4 cycles - 3 byte
pha // 3 cycles - 1 byte
ldy #0 // 2 cycles - 2 byte
sty $d507 // 4 cycles - 3 byte
ldy #1 // 2 cycles - 2 byte
sty $d509 // 4 cycles - 3 byte
ldx TEMP // 3 cycles - 2 bytes
txs // 2 cycles - 1 byte
cli // 2 cycles - 1 byte
rts // 6 cycles - 1 byte
Pure copy requires 1538 cycles, full subroutine requires 1590 cycles. The improvement compared to the single relocation solution is 44%. Subroutine size increased to 804 bytes.